
[Redis] Cache 전략
Cache Warming : 미리 DB 데이터를 cache에 말아두는 작업
캐싱지침
읽기 전략
- Look Aside 패턴 → 캐시 미스 시 DB 조회
- 원하는 데이터만 별도로 구성하여 캐시에 저장
- DB와 캐시가 분리 가용되기 때문에 캐시 장애 대비 구성이 되어있음
- Redis 다운시 순간적으로 DB로 부하가 몰릴 순 있음

- Read Through 패턴 → 캐시 미스 시 DB 조회 후 캐시 업데이트 후 캐시를 읽음
- DB와 캐시간 데이터 동기화가 항상 이루어져 데이터 정합성 보장
- DB 동기화를 캐시 라이브러리에 위임
- 데이터 조회 속도가 전체적으론 느림 (캐시 2번 조회하니)
- Redis가 다운될 경우 서비스 이용 불가

쓰기 전략
- Write Back 패턴 → 쓰기 작업 시에 캐시에 모아서 배치 작업을 통해 DB에 반영
- Wirte가 빈번하면서 Read 하는 양이 많은 서비스에 적합
- 자주 사용되지 않는 불필요한 리소스가 저장됨
- 캐시에서 오류 발생 시 데이터 영구 소실

- Wirte Through 패턴
- 데이터 일관성을 유지 할 수 있음. (유실되면 안되는 상황에 적합)
- 자주 사용되지 않는 불필요한 리소스가 저장
- 매 요청마다 두번의 Write 발생으로 빈번한 update 서비스에서 성능 이슈 발생

위의 두 쓰기 전략은 모두 불필요한 리소스가 저장 될 수 있으므로 TTL 설정을 통해 사용되지 않는 데이터를 삭제해야함 (expire 명령어)
- Wirte Around 패턴
- 모든 데이터는 DB에 저장(캐시 갱신안함)
- 캐시 미스일때만 DB, 캐시 데이터 저장 → 그래서 캐시와 db 데이터가 다를 수 있으므로 TTL 짧게 가져가야함
- Wirte Through보다 훨씬 빠름

Cache Stampede : 캐시 키가 만료되는 순간과 조회 시점이 겹치게 될 때 모든 서버들이 DB가서 데이터를 질의하는 duplicate read 와 그 값을 반복적으로 redis에 write하는 duplcate write 가 발생
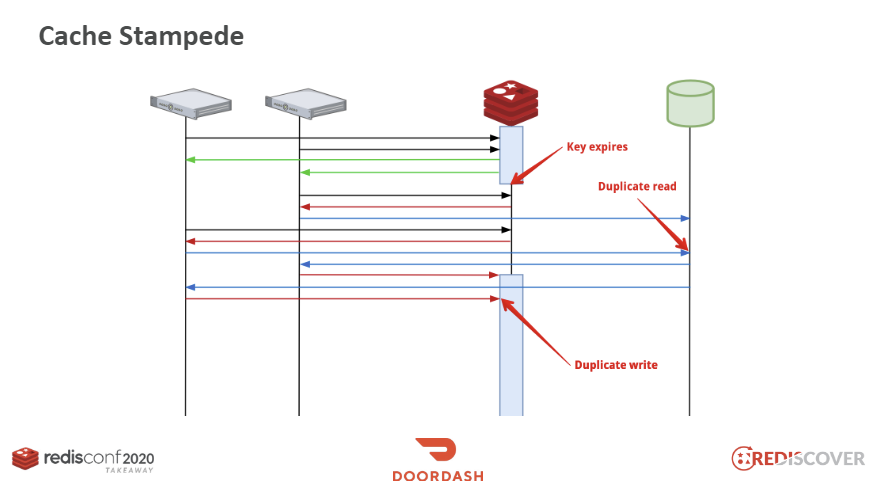
PER(Probablistic Early Recomputation) 알고리즘 도입으로 해결 → https://meetup.nhncloud.com/posts/251
레디스 활용 사례를 보면 좋아요시에 Redis에 적어놨다가 db에 배치하는 걸 추천

Cache를 Write-Through 하기 위한 방법 구현은 어떻게 될까?
Write-Through
- 데이터 읽기 (Read):
- 클라이언트가 데이터를 요청하면 먼저 Redis 캐시에서 데이터를 검색합니다.
- 캐시에 데이터가 있으면 그 데이터를 반환합니다 (캐시 히트).
- 캐시에 데이터가 없으면 (캐시 미스), 데이터베이스에서 데이터를 읽어오고, 그 데이터를 Redis 캐시에 저장한 후 클라이언트에 반환합니다.
- 데이터 쓰기 (Write):
- 클라이언트가 데이터를 업데이트하거나 삽입 요청을 하면, Redis 캐시와 데이터베이스에 동시에 데이터를 씁니다.
- 데이터를 Redis 캐시에 쓰는 작업과 데이터베이스에 쓰는 작업을 동시에 수행하여 일관성을 유지합니다.
고려사항
- 트랜잭션 관리:
- 데이터베이스와 Redis 캐시에 동시에 쓰기를 수행하는 동안 오류가 발생할 수 있으므로, 트랜잭션 관리가 필요
- Redis 트랜잭션과 데이터베이스 트랜잭션을 적절히 사용하여 데이터 일관성을 보장
- 오류 처리:
- 데이터베이스 쓰기 또는 Redis 쓰기 중 하나가 실패하는 경우 이를 처리하는 로직이 필요
- 실패 시 재시도 메커니즘을 구현하거나, 로그를 기록하고 관리하는 방법을 고려
- 성능 최적화:
- 데이터베이스와 Redis에 동시에 쓰기를 수행하므로 쓰기 작업의 성능이 중요
- 비동기 쓰기 또는 배치 처리와 같은 성능 최적화 기법을 고려
- 데이터 일관성:
- Redis와 데이터베이스 간의 데이터 일관성을 유지하기 위해 쓰기 작업의 순서를 보장해야 함
- 분산 시스템 환경에서는 분산 트랜잭션 관리 기법을 사용할 수 있음 → Lettuce 스핀락 방식
Spring에서 구현할 때
- Read는 @Cacheable 사용하면 됨. (캐시가 있으면 캐시를, 없으면 db조회)
- Write 할 때는 @CachePut 어노테이션을 사용하면 될 듯
이런식으로...
@Service
class MyService(
private val myEntityRepository: MyEntityRepository
) {
@Cacheable(value = ["myCache"], key = "#key")
fun readFromCache(key: String): String? {
val entity = myEntityRepository.findById(key).orElse(null)
return entity?.value
}
@CachePut(value = ["myCache"], key = "#key")
@Transactional
fun writeToCacheAndDb(key: String, value: String): String {
val entity = MyEntity(key, value)
myEntityRepository.save(entity)
return value
}
@CacheEvict(value = ["myCache"], key = "#key")
@Transactional
fun deleteFromCacheAndDb(key: String) {
myEntityRepository.deleteById(key)
}
}필터 별로 보여줘야 하는 리스트는 어떻게 캐싱해야 할까?
Sorted Sets
Redis의 Sorted Sets 데이터 구조를 사용하면 score를 기준으로 데이터가 자동 정렬된다. 그럼 포스트 생성 시간, 좋아요 수, 조회 수 등을 스코어로 사용할 수 있다. (우리가 필터별로 데이터를 말아 둘 필요가 없다는 것)
각 게시글의 상세 데이터는 hash로 저장한다. (K-V 형태)
정렬 기능은 posts_by_views , posts_by_likes 이런 식으로 Sorted Set을 만들어 사용할 수 있을 것 같다.
게시글 저장 시 각 기준에 맞는 점수로 Sorted Set에 추가.
zrevrange
게시글 ID를 최신 순으로 가져오고 해당 ID로 상세 정보를 Hash에서 조회한다.
해당 명령어의 시작과 끝 인덱스를 조절해서 페이징 기능을 구현할 수 있다. ex) 페이지당 10개를 보여주려고 할 때 zrevrange("posts",0,9)
@Service
class PostService @Autowired constructor(private val redissonClient: RedissonClient) {
private val sortedSetKey = "posts:latest"
fun addPost(post: Post) {
val sortedSet: RSortedSet<Post> = redissonClient.getSortedSet(sortedSetKey)
sortedSet.add(post)
}
fun getPosts(start: Int, count: Int): List<Post> {
val sortedSet: RSortedSet<Post> = redissonClient.getSortedSet(sortedSetKey)
return sortedSet.valueRange(start.toLong(), (start + count - 1).toLong()).toList()
}
}
@RestController
class PostController(private val postService: PostService) {
@GetMapping("/api/posts")
fun getPosts(
@RequestParam(defaultValue = "0") start: Int,
@RequestParam(defaultValue = "10") count: Int
): List<Post> {
return postService.getPosts(start, count)
}
}
이러면 무한 스크롤 페이징 처리도 구현 가능
근데 다음페이지로 갈 때 Sorted Set에 데이터가 추가 되면 어떨까?
고유 식별자 기반 페이징
fun getPostsByCriteria(jedis: Jedis, criteria: String, lastId: String?, count: Int): List<String> {
val sortedSetKey = when (criteria) {
"likes" -> "posts:likes"
"views" -> "posts:views"
"purchases" -> "posts:purchases"
"latest" -> "posts:latest"
else -> throw IllegalArgumentException("Unknown criteria")
}
val sortedSet: RSortedSet<Post> = redissonClient.getSortedSet(sortedSetKey)
val range = if (lastId == null) {
sortedSet.valueRange(0, count.toLong())
} else {
val lastPost = sortedSet.get(lastId)
sortedSet.valueRange(lastPost, count.toLong())
}
return range
}lastId는 마지막 조회된 데이터 ID. 데이터 삽입 시에 ID를 기준으로 페이징을 조정할 수 있다.
스냅샷 기반 페이징
fun getPostsSnapshot(start: Int, count: Int): List<String> {
// 스냅샷을 생성
val snapshot = redissonClient.getSortedSet("posts:latest").toSortedSet()
return snapshot.valueRange(start.toLong(), (start + count - 1).toLong()).toList()
}데이터를 정렬한 상태의 스냅샷을 유지하고 해당 스냅샷 기반으로 페이징 수행 할 수 있다. 그러면 데이터 삽입 시에도 페이지 일관성 유지.
페이징 토큰 사용
fun getPostsWithToken(jedis: Jedis, criteria: String, pageToken: String?, count: Int): List<String> {
val sortedSetKey = when (criteria) {
"likes" -> "posts:likes"
"views" -> "posts:views"
"purchases" -> "posts:purchases"
"latest" -> "posts:latest"
else -> throw IllegalArgumentException("Unknown criteria")
}
val sortedSet: RSortedSet<Post> = redissonClient.getSortedSet(sortedSetKey)
val range = if (pageToken == null) {
sortedSet.valueRange(0, count.toLong())
} else {
val lastPost = sortedSet.get(pageToken)
sortedSet.valueRange(lastPost, count.toLong())
}
return range.map { it.id }
}
pageToken은 마지막으로 조회된 항목의 ID 또는 다른 고유 식별자. 사용자가 스크롤 할 때 마지막으로 조회된 항목을 기준으로 다음 항목 조회
하나의 스냅샷을 저장하여 사용자에게 제공
@Cacheable("posts-snapshot")
fun getPostsSnapshot(count: Int): List<Post> {
val sortedSet: RSortedSet<Post> = redissonClient.getSortedSet("posts:latest")
return sortedSet.valueRange(0, count.toLong()).toList()
}
서버에서 정렬된 결과의 스냅샷을 일정 시간동안 캐시해서 클라이언트에 제공.
데이터 일관성 유지 + 성능 최적화가 가능
<레퍼런스>
Redis pagination - 레디스에서 페이징 처리 / 페이징 처리 방법에 따른 고려사항 TPS
Redis 에 @Cacheable, @CachePut, @CacheEvict 적용해보기
[REDIS] 📚 캐시(Cache) 설계 전략 지침 💯 총정리
캐시 성능 향상기 (Improving Cache Speed at Scale) (nhn cloud)
Sorted Set Introduction (명령어)
'Back-end' 카테고리의 다른 글
| [gRPC] gRPC란 (3) | 2024.10.02 |
|---|---|
| [Spring/Thymeleaf] option 태그에 enum 동적으로 넣기 (0) | 2024.08.10 |
| Redis의 분산락 사용에 대해서 (0) | 2024.07.19 |
| [C#] using 구문 (1) | 2022.09.08 |
| [Node.js] NVM으로 여러 버전의 node.js 사용하기 (0) | 2022.07.20 |